EPC Gen2 builds on slot Aloha, which has a crucial nature:
Max Throughput = 1 / e = 36.79%
Simulator generates the result around 34% (above 1000 tags)
Now the concentrates are on:
Reduce Q parameter update frequency: as far as we know, Q parameter decreases as the detection process going. Fluctuating Q causes redundant data in transmission.
Find an out of box method to break the slot Aloha throughput limit.
Wednesday, December 19, 2007
Friday, December 14, 2007
Slot-count(Q) selection algorithm
Slot-count(Q) selection algorithm is a recommendation algorithm, which is accompanied with EPC Gen2. It seems the protocol doesn't mention in what case to use this algorithm and update Q parameter, so I think this is left to the designer to deal with or even you can have you own Q generating algorithm. This algorithm is not necessary a part of EPC Gen2 protocol.
Thursday, December 13, 2007
EPC Gen2 Pseudo Code

I use Java to implement this algorithm. This can simulate the communication between tags and reader, and statistics can be collected in each cycle or slot.
It is still unclear about when to update tag's Q parameter. This algorithm assumes it updating each collision or some empty cycles.
The performance is mentioned in previous blog entry. Basically, three cycles for identifying one tag.
Wednesday, December 12, 2007
Made the First simulation
Run the first simulation. It seems all good to the simulator, but the result of performance is under my expectation, as most of the time, collision happens.
Crucial Issues:
How frequent to update Q parameter using that official algorithm?
Every queryRep queryAdjust or follow other rule
The rule, or the way to adjust the gap (the C parameter) in each update of Q parameter.
Brief Performance Summary:
Tags Number * 3 = Query Number (20 - 5000 tags)
Three query messages needed to identify one tag
Crucial Issues:
How frequent to update Q parameter using that official algorithm?
Every queryRep queryAdjust or follow other rule
The rule, or the way to adjust the gap (the C parameter) in each update of Q parameter.
Brief Performance Summary:
Tags Number * 3 = Query Number (20 - 5000 tags)
Three query messages needed to identify one tag
Wednesday, December 05, 2007
Detail in Class 1 and Implement Gen2
Passive Tag Transmission in Class 1:
5.2. Reader-Tag Half-Duplex Communication
As specified in Section 6, the Reader-to-Tag and Tag-to-Reader communication occurs in a half-duplex manner. The Reader initiates communication by modulating a complete command. The Reader then transmits an unmodulated continuous wave (CW) signal. The Tag modulates its reflection of the CW signal (backscatter communication).
5.3. Reader-to-Tag Communication Signals
A Reader may emit no signals at any frequency, may emit a CW signal at a single frequency, or may emit a modulated signal at a single frequency.
5.3.1. Reader-to-Tag Signal Modulation Depth
The Reader communicates with tags using Amplitude Shift Keying (ASK) with a minimum modulation depth of 30% and a maximum modulation depth of 100%. Modulation shape, depth and rate of modulation are variable within the limits described below. Compliant Tags will adjust their timing over a range of modulation rates to lock to reader transmissions automatically during the [CLKSYNC] period of a Reader command.
Have read Class 1 Gen2 specification, draft the pesudo-code framework using Java. Thinking about a whether a discrete simulation is necessary, and the means of performance measurement.
In implement simulation of Gen2, a simplification is made in message transmission, like ACK and Session selection etc., which have no influence in the anti-collision measurement so far.
Session selection deals with Reader-to-Reader collision.
ACK is reliable transmission and for further processing in tag.
5.2. Reader-Tag Half-Duplex Communication
As specified in Section 6, the Reader-to-Tag and Tag-to-Reader communication occurs in a half-duplex manner. The Reader initiates communication by modulating a complete command. The Reader then transmits an unmodulated continuous wave (CW) signal. The Tag modulates its reflection of the CW signal (backscatter communication).
5.3. Reader-to-Tag Communication Signals
A Reader may emit no signals at any frequency, may emit a CW signal at a single frequency, or may emit a modulated signal at a single frequency.
5.3.1. Reader-to-Tag Signal Modulation Depth
The Reader communicates with tags using Amplitude Shift Keying (ASK) with a minimum modulation depth of 30% and a maximum modulation depth of 100%. Modulation shape, depth and rate of modulation are variable within the limits described below. Compliant Tags will adjust their timing over a range of modulation rates to lock to reader transmissions automatically during the [CLKSYNC] period of a Reader command.
Have read Class 1 Gen2 specification, draft the pesudo-code framework using Java. Thinking about a whether a discrete simulation is necessary, and the means of performance measurement.
In implement simulation of Gen2, a simplification is made in message transmission, like ACK and Session selection etc., which have no influence in the anti-collision measurement so far.
Session selection deals with Reader-to-Reader collision.
ACK is reliable transmission and for further processing in tag.
Thursday, November 29, 2007
Benchmark Protocol
The benchmark algorithm: EPC Class1 protocol, which is developed upon binary tree algorithm
To my knowledge, two stream algorithms both have its own pros and cons, which mostly depends on the environment they are working in, or tasks they are dealing with. Environment like number of tags can exist is a typical consideration in choosing which algorithm to use. Different tasks like detect the existing of tags or monitor tags existing constantly are to be concerned. So it is hard to say one kind of or specific one algorithm is much better others. My point is it depends on the practical situation in our application.
Example, a system to check out in a supermarket may only detect the existing of an item once, whereas, a system to monitor goods in a fridge may sense the same item many time. First scenario mostly has different items in every sensing, but the later one may sensing mostly the same item constantly. Unfortunately, current algorithms only deal one scenario well, or good at one scenario comparing to the other algorithms.
The trend is class 1 Gen2 those days. I will implement Class 1 first, and then extend to Gen2. These two algorithms have been already standarized, and implemented in industry.
An explanation of EPCGlobal class 0, class 1, class 1 Gen2
http://www.enigmatic-consulting.com/Communications_articles/RFID/RFID_protocols.html
Official website for documentation of these protocols:
http://www.epcglobalinc.org/standards/
To my knowledge, two stream algorithms both have its own pros and cons, which mostly depends on the environment they are working in, or tasks they are dealing with. Environment like number of tags can exist is a typical consideration in choosing which algorithm to use. Different tasks like detect the existing of tags or monitor tags existing constantly are to be concerned. So it is hard to say one kind of or specific one algorithm is much better others. My point is it depends on the practical situation in our application.
Example, a system to check out in a supermarket may only detect the existing of an item once, whereas, a system to monitor goods in a fridge may sense the same item many time. First scenario mostly has different items in every sensing, but the later one may sensing mostly the same item constantly. Unfortunately, current algorithms only deal one scenario well, or good at one scenario comparing to the other algorithms.
The trend is class 1 Gen2 those days. I will implement Class 1 first, and then extend to Gen2. These two algorithms have been already standarized, and implemented in industry.
An explanation of EPCGlobal class 0, class 1, class 1 Gen2
http://www.enigmatic-consulting.com/Communications_articles/RFID/RFID_protocols.html
Official website for documentation of these protocols:
http://www.epcglobalinc.org/standards/
Wednesday, November 28, 2007
Research on Current Technique
We can identify the collision bit by bit if Manchester coding is used. This possibility is useful when there is not many tags in an interrogation area.
Weakness of Passive Tag:
Tag collisions is problematic as a tag has limited power and functionality. A passive tag can only transmit data by reflecting the reader transmitted electromagneticwaves, and hence, cannot detect nor communicate with the neighboring tags. The energy received by a tag is usually less than 100μW. Accordingly, CSMA-related methods are not practical anti-collision algorithms for the passive tags.
ISO 14443-3
Type A bit collision detection
Type B series of command sequence
ISO 15693
More detail about ISO, they are not just anti-collision protocols.
http://rfidwizards.com/index.php?option=com_content&task=view&id=242&Itemid=174
After review some anti-collision articles, I find out there are two main streams of anti-collision algorithm: ALOHA based and tree based. First one is probabilistic and the last one is deterministic.
After one weak research, I finished the first step in reviewing current papers about those proposed algorithms, and have better understanding the constrains existed in development process. I will concentrate on the most common scenario: passive tags with one reader sharing one channel, to consider the algorithm. Next step is brainstorming.
Weakness of Passive Tag:
Tag collisions is problematic as a tag has limited power and functionality. A passive tag can only transmit data by reflecting the reader transmitted electromagneticwaves, and hence, cannot detect nor communicate with the neighboring tags. The energy received by a tag is usually less than 100μW. Accordingly, CSMA-related methods are not practical anti-collision algorithms for the passive tags.
ISO 14443-3
Type A bit collision detection
Type B series of command sequence
ISO 15693
More detail about ISO, they are not just anti-collision protocols.
http://rfidwizards.com/index.php?option=com_content&task=view&id=242&Itemid=174
After review some anti-collision articles, I find out there are two main streams of anti-collision algorithm: ALOHA based and tree based. First one is probabilistic and the last one is deterministic.
After one weak research, I finished the first step in reviewing current papers about those proposed algorithms, and have better understanding the constrains existed in development process. I will concentrate on the most common scenario: passive tags with one reader sharing one channel, to consider the algorithm. Next step is brainstorming.
Friday, November 23, 2007
Understanding what have been achieved so far
Constraints in RFID communication in particular:
i. Lack of internal power source in the passive tags. This requires the tag reader to powerupthese tags whenever it needs to communicate with them.
ii. Total number of tags is unknown.
iii. Tags cannot communicate with each other. Hence collision resolution needs to be doneat the tag reader.
iv. Limited memory and computational capabilities at the tag. Thus the resolution protocolmust be simple and incur minimum overhead from the tag’s perspective.
Measurement in RFID anti-collision performance:
a. Minimal Delay: Time taken for identification of all the tags should be low. From a userpoint of view, this should not be perceptible.
b. Power consumption: Due to the absence of an internal power source, power consumedby the tags should be minimal. The amount of power consumed is influenced by the totalnumber of replies sent by each of the tags. An efficient protocol will minimize themessages between the tag and tag reader.
c. Reliability and Completeness: All the tags in the range of the tag reader should getidentified correctly.
d. Line-of-sight Independence: The object attached with the tag can be located anywhereas long as they are in the range of the tag reading device.
e. Robustness: The protocol should work irrespective of environmental conditions.
f. Scalability: The protocol should be scalable to accommodate an increase in the numberof tags.
Four basic algorithms in RFID:
i. Lack of internal power source in the passive tags. This requires the tag reader to powerupthese tags whenever it needs to communicate with them.
ii. Total number of tags is unknown.
iii. Tags cannot communicate with each other. Hence collision resolution needs to be doneat the tag reader.
iv. Limited memory and computational capabilities at the tag. Thus the resolution protocolmust be simple and incur minimum overhead from the tag’s perspective.
Measurement in RFID anti-collision performance:
a. Minimal Delay: Time taken for identification of all the tags should be low. From a userpoint of view, this should not be perceptible.
b. Power consumption: Due to the absence of an internal power source, power consumedby the tags should be minimal. The amount of power consumed is influenced by the totalnumber of replies sent by each of the tags. An efficient protocol will minimize themessages between the tag and tag reader.
c. Reliability and Completeness: All the tags in the range of the tag reader should getidentified correctly.
d. Line-of-sight Independence: The object attached with the tag can be located anywhereas long as they are in the range of the tag reading device.
e. Robustness: The protocol should work irrespective of environmental conditions.
f. Scalability: The protocol should be scalable to accommodate an increase in the numberof tags.
Four basic algorithms in RFID:
- Splitting or Tree Search, use coin flipping or tag ID, needs feedback from reader, and counter
- Memoryless or Query Tree, maximum number of tag assumed, prefix p, feedback each cycle, no counter. This algorithm sometimes is refered as Binary Tree in many literatures
- I-Code or frame-slotted Aloha, not 100% detection of tag, need experimental measurement in refining protocol, particular in estimating number of tags
- Contactless, special modulation: 00ZZ->0, ZZ00-> 1
Source:
C. Abraham, V. Ahuja, A.K. Ghosh, P. Pakanati, InventoryManagement using Passive RFID Tags: A Survey, Department ofComputer Science, The University of Texas at Dallas, Richardson,Texas, pp. 1–16, October, 2002.
This is a very good paper, which is almost the first part of
Taxonomy and survey of RFID anti-collision protocols DH Shih, PLSun, DC Yen, SM Huang - Computer Communications, 2006
Standard Protocols:
EPCglobal Bit-based Avg. : 200 tags/sCLASS 0 Binary tree Max. : 800 tags/s(UHF) (Deterministic)
EPCglobal Binary tree Not specifiedCLASS 1 (Bin slot)(UHF) (Probabilistic)
ISO 18000-6 Dynamic Avg. : 100 tags/sTYPE - A Framed ALOHA(UHF) (Probabilistic)
ISO 18000-6 Binary Tree Avg. : 100 tags/sTYPE - B (Probabilistic)(UHF)
Binary Tree and Dynamic Frame-Slot Aloha(DFSA) are two commonly implemented algorithms. Grouping is a major investigating area in improving DFSA.
SSim - a Simple Discrete-Event Simulation Library:
First Day Research, deciding which path to go
Search some books about network simulation in the library.
Search the existed RFID simulator. Most of them are not on MAC level, but on application level, to help software programmer develop RFID application in real business case.
About Simulator:
NS-2 needs C++ and OTcl. After brief reading of the NS2 manual, I found out C++ must be used to customize the protocol. It seems not enough time to build the project upon this simulator. Lots of project built up based on performance measurement by this simulator, which is the benefit in using this tool.
J-Sim is out of date, not enough reference can be a problem.
Next Step
As to get familiar with simulator cost too much time, next step is to search the material in NS2 simulation, if these materials are insufficient in shortening the developing time, I may consider to build my own simulator, like the one we use in COMP5416
Search the existed RFID simulator. Most of them are not on MAC level, but on application level, to help software programmer develop RFID application in real business case.
About Simulator:
NS-2 needs C++ and OTcl. After brief reading of the NS2 manual, I found out C++ must be used to customize the protocol. It seems not enough time to build the project upon this simulator. Lots of project built up based on performance measurement by this simulator, which is the benefit in using this tool.
J-Sim is out of date, not enough reference can be a problem.
Next Step
As to get familiar with simulator cost too much time, next step is to search the material in NS2 simulation, if these materials are insufficient in shortening the developing time, I may consider to build my own simulator, like the one we use in COMP5416
Thursday, November 22, 2007
Design of a RFID anti-collision protocol for RFID Tag-Reader Communications
Project Topic:
Due to the receding cost of manufacturing, Radio Frequency Identification (RFID) systems are used in a variety of applications to tag and track physical objects. A typical RFID system operation involves numerous tags to be present simultaneously in the interrogation zone of a single reader. Any responses from the tags can collide, leading to retransmission of tag information that results in increase in the access delay. Besides, readers physically located near one another may interfere each other. Such reader collision must be minimized. In this project, we will design a procedure to deal with tag and reader problems, while taking environmental effects into account.
===========RFID====ERA=============
Due to the receding cost of manufacturing, Radio Frequency Identification (RFID) systems are used in a variety of applications to tag and track physical objects. A typical RFID system operation involves numerous tags to be present simultaneously in the interrogation zone of a single reader. Any responses from the tags can collide, leading to retransmission of tag information that results in increase in the access delay. Besides, readers physically located near one another may interfere each other. Such reader collision must be minimized. In this project, we will design a procedure to deal with tag and reader problems, while taking environmental effects into account.
===========RFID====ERA=============
Thursday, October 18, 2007
Integrate our components into Sakai
This week
This week we start to integrate all our components. Actually four components are working till now in our group. What we do is put these four components as four tools together under one site.
This is actually a group work, then I tried to put two guys tools in Sakai in my desktop environment, finally I got one worked but another one didn't. The problem mostly from setup database.
I use HSQLDB, some guys use MySQL. So I have to configure my computer to provide MySQL service. After that, I have to create table and insert data using some function provided by each component, which is various. So I think documentation in how to localize a component into a computer is very important. Example like most components specify a local path in connecting database. By the way, I write a Readme.txt for my group member for instruction.
It is almost to the end of this course. I learnt lots of new things through this course, and start to know what is software engineering. It is not very interesting as I thought before, especially we use some tool like Sakai. It is not properly documented and not well supported by large community. Another thing I dislike is debug. Debug is normal in programming, but 3/4 of the time taken up by debug is not exciting isn't it? Luckily, we have Junit, and Ant, Maven to support in developing. Those are very handy tools. Otherwise, 99% is debug time.
Bugs are caused by different reasons.
The common one is rush programming, or trial programming. Since all those frameworks are new to me, there are different ways to fulfill a task or a function, most case I implement some logic and see whether they will work. This should belong to normal programming process, trial and debug.
Another reason is version uncompatible. Most of the time, I follow the literature, but found out I use an old version of Jar or a too new version of Jar. Then I have to give up following the example and search for other example code. A very good case is Hibernate2 and 3. They use different import path, which means once you change the version, you must change your code. And thing can be more complex. When you use Spring, it support Hibernate, but you should figure out which version it supports. When you find out a good example from Spring2, and want to use it, maybe you have to change your hibernate code in deploy to Spring 2. Then later you find out Sakai doesn't support Spring 2, then you will have to change all things back manually.
Other reason can be not proper test of code. The software provider doesn't test their code properly then release the version. The case is Mevenide in Linux, which is a rubbish plug-in, don't try to use this like Ant in your Eclipse.
The course
This course gives you pressure to learn more than teach you things. It schedules project and ask you to know, to figure out tones of problem. It is OK, since this is a practical way to understand software development.
But the group project comes out not much like cooperating work. As our components are not integratable practically when we start individually. And it is beyond the initial idea of cooperated work by using Trac and SVN. (they are not good tools, at least what we are using are bad) A little bit disappointed about the misleading at the beginning.
This week we start to integrate all our components. Actually four components are working till now in our group. What we do is put these four components as four tools together under one site.
This is actually a group work, then I tried to put two guys tools in Sakai in my desktop environment, finally I got one worked but another one didn't. The problem mostly from setup database.
I use HSQLDB, some guys use MySQL. So I have to configure my computer to provide MySQL service. After that, I have to create table and insert data using some function provided by each component, which is various. So I think documentation in how to localize a component into a computer is very important. Example like most components specify a local path in connecting database. By the way, I write a Readme.txt for my group member for instruction.
It is almost to the end of this course. I learnt lots of new things through this course, and start to know what is software engineering. It is not very interesting as I thought before, especially we use some tool like Sakai. It is not properly documented and not well supported by large community. Another thing I dislike is debug. Debug is normal in programming, but 3/4 of the time taken up by debug is not exciting isn't it? Luckily, we have Junit, and Ant, Maven to support in developing. Those are very handy tools. Otherwise, 99% is debug time.
Bugs are caused by different reasons.
The common one is rush programming, or trial programming. Since all those frameworks are new to me, there are different ways to fulfill a task or a function, most case I implement some logic and see whether they will work. This should belong to normal programming process, trial and debug.
Another reason is version uncompatible. Most of the time, I follow the literature, but found out I use an old version of Jar or a too new version of Jar. Then I have to give up following the example and search for other example code. A very good case is Hibernate2 and 3. They use different import path, which means once you change the version, you must change your code. And thing can be more complex. When you use Spring, it support Hibernate, but you should figure out which version it supports. When you find out a good example from Spring2, and want to use it, maybe you have to change your hibernate code in deploy to Spring 2. Then later you find out Sakai doesn't support Spring 2, then you will have to change all things back manually.
Other reason can be not proper test of code. The software provider doesn't test their code properly then release the version. The case is Mevenide in Linux, which is a rubbish plug-in, don't try to use this like Ant in your Eclipse.
The course
This course gives you pressure to learn more than teach you things. It schedules project and ask you to know, to figure out tones of problem. It is OK, since this is a practical way to understand software development.
But the group project comes out not much like cooperating work. As our components are not integratable practically when we start individually. And it is beyond the initial idea of cooperated work by using Trac and SVN. (they are not good tools, at least what we are using are bad) A little bit disappointed about the misleading at the beginning.
Monday, October 08, 2007
My Project into Sakai

Follow the instruction in the doc, download sakai.bibliography example, put the weg/ file to maven/repository/, be sure to add a dependency in project.xml of the sakai-tool-filter-1.0.jar
My problem is:
My welcome page is a static page, rather than a redirect page. When it first shows the welcome page, it can't link to those jsp page under jsp/. Then after an hour test, I start to redirect this page to a page under jsp/. Now it is working well. After redirect to a jsp page, you still can link back to that static page, the interesting thing is, now this static page starts to work.
Refer to the sakai.bibliography example, I add a header to my page, and some format, which makes my pages looked very nice. You can have the whole page in the screen, instead scrolling the bar. The thing to control these format is under include.jsp file and a sakai.jsp related.
I should say Sakai is lack of documentation as what we usually do in our program development.
Wednesday, October 03, 2007
REFINE of My project, Touch Sakai
A pure Sakai Demo without my project
Running on my computer

The syntax has different views between IE and FireFox:

The view in FireFox

The view in IE
HSQLDB: start up:
java -classpath hsqldb-1.7.3.0.jar org.hsqldb.Server
Running on my computer

The syntax has different views between IE and FireFox:

The view in FireFox

The view in IE
HSQLDB: start up:
java -classpath hsqldb-1.7.3.0.jar org.hsqldb.Server
Wednesday, September 26, 2007
Data Persisternt
After install MySQL:
sudo /etc/init.d/mysql stop
mysqladmin -u root password myPassword
mysql -u root -p
sudo /etc/init.d/mysql start
Current ID and PS
ID: root
PS: root
Unit Test, Add this to project.properties
maven.junit.fork=true
Reason:
http://forum.springframework.org/archive/index.php/t-23057.html
Finally, my Hibernate is working,
NB>the object ID value cant be set by programmer, it will specify by the application, which is hibernate or database.
Many legacy SQL data models use natural primary keys. A natural key is a key with
business meaning: an attribute or combination of attributes that is unique by virtue
of its business semantics. Examples of natural keys might be a U.S. Social Security
Number or Australian Tax File Number. Distinguishing natural keys is simple: If a
candidate key attribute has meaning outside the database context, it’s a natural
key, whether or not it’s automatically generated.
Experience has shown that natural keys almost always cause problems in the
long run. A good primary key must be unique, constant, and required (never null
or unknown). Very few entity attributes satisfy these requirements, and some that
do aren’t efficiently indexable by SQL databases. In addition, you should make
absolutely certain that a candidate key definition could never change throughout
he lifetime of the database before promoting it to a primary key. Changing the
definition of a primary key and all foreign keys that refer to it is a frustrating task.
For these reasons, we strongly recommend that new applications use synthetic
identifiers (also called surrogate keys). Surrogate keys have no business meaning—
they are unique values generated by the database or application. There are a num-
ber of well-known approaches to surrogate key generation.
from Hibernate in Action Page90 -Page91
Also, the ID should be int, short or long. Cant be String!!!!!!
Again, don't give value to ID.
I have tried some unit tests. I planned to do this by the end, but the code is too many to test, and debug, so the only wayto narrow your test and find the problem is pick up Unit Test. The Test-Record really helps.
sudo /etc/init.d/mysql stop
mysqladmin -u root password myPassword
mysql -u root -p
sudo /etc/init.d/mysql start
Current ID and PS
ID: root
PS: root
Unit Test, Add this to project.properties
maven.junit.fork=true
Reason:
http://forum.springframework.org/archive/index.php/t-23057.html
Finally, my Hibernate is working,
NB>the object ID value cant be set by programmer, it will specify by the application, which is hibernate or database.
Many legacy SQL data models use natural primary keys. A natural key is a key with
business meaning: an attribute or combination of attributes that is unique by virtue
of its business semantics. Examples of natural keys might be a U.S. Social Security
Number or Australian Tax File Number. Distinguishing natural keys is simple: If a
candidate key attribute has meaning outside the database context, it’s a natural
key, whether or not it’s automatically generated.
Experience has shown that natural keys almost always cause problems in the
long run. A good primary key must be unique, constant, and required (never null
or unknown). Very few entity attributes satisfy these requirements, and some that
do aren’t efficiently indexable by SQL databases. In addition, you should make
absolutely certain that a candidate key definition could never change throughout
he lifetime of the database before promoting it to a primary key. Changing the
definition of a primary key and all foreign keys that refer to it is a frustrating task.
For these reasons, we strongly recommend that new applications use synthetic
identifiers (also called surrogate keys). Surrogate keys have no business meaning—
they are unique values generated by the database or application. There are a num-
ber of well-known approaches to surrogate key generation.
from Hibernate in Action Page90 -Page91
Also, the ID should be int, short or long. Cant be String!!!!!!
Again, don't give value to ID.
I have tried some unit tests. I planned to do this by the end, but the code is too many to test, and debug, so the only wayto narrow your test and find the problem is pick up Unit Test. The Test-Record really helps.
Monday, September 17, 2007
Maven and Tomcat
Deploy to Tomcat using maven.xml file:
Two sources about deploy to Tomcat using Maven 1.0.2, basically, it follows the Ant structure: add these code to maven.xml
http://raibledesigns.com/rd/entry/running_cargo_from_maven
http://raibledesigns.com/rd/entry/maven_console_and_setting_propertiesTwo sources about deploy to Tomcat using Maven 1.0.2, basically, it follows the Ant structure: add these code to maven.xml
http://raibledesigns.com/rd/entry/running_cargo_from_maven
To deploy a web application to Tomcat, just copy the war file to /tomcat/webapps/
Once Tomcat starts up, it will automatically scan this folder, and generates a sub directory under this folder according to the .war file. You can use
tail -f /tomcat/logs/catalina.out
to check Tomcat's reaction to your deploy.
One thing is you don't have to keep on shutdown and start tomcat after your deploy. Tomcat keeps on scan webapps folder after it starts.
The other way is using Maven-Tomcat plugin, which is provided by 3rd party--codeczar.
About Java Bean:
property(in XML file) -------- setProperty(), getProperty() (Methods in Java Bean)
attributes name seems unrelated to property.
To install SVN in Eclipse:
Name: Subclipse 1.2.x (Eclipse 3.2+)
URL: http://subclipse.tigris.org/update_1.2.x
Name: Subclipse 1.0.x (Eclipse 3.0/3.1)
URL: http://subclipse.tigris.org/update_1.0.x
URL: http://subclipse.tigris.org/update_1.0.x
Our team location:
http://svn.ug.it.usyd.edu.au/svn/ebus5003_4
http://svn.ug.it.usyd.edu.au/svn/ebus5003_4
Thursday, September 13, 2007
Mevenide working fina!!!!!!!!!!!!!!!!y in Eclipse
1. Set my Mevenide in Preference:
Java Home point to /jre:
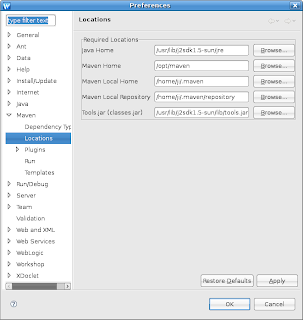
2. In Eclipse: Add one line below: based on your JDK version
(Window | Preferences | Java | Installed JREs | | Edit): 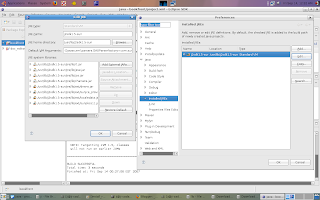
A discussion here:
Java Home point to /jre:

2. In Eclipse: Add one line below: based on your JDK version
(Window | Preferences | Java | Installed JREs |
Default VM Arguments:
JDK 1.5 or 1.6
-Djavax.xml.parsers.SAXParserFactory=com.sun.org.apache.xerces.internal.jaxp.SAXParserFactoryImpl
JDK 1.4 -
-Djavax.xml.parsers.SAXParserFactory=org.apache.crimson.jaxp.SAXParserFactoryImpl
Refer to: http://www.xmlblaster.org/FAQ.html#xml-parser

3. Copy /MAVEN_HOME/bin to /home/ji (my home address)
in order to let Mevenide find forehead.conf
A discussion here:
http://jira.codehaus.org/browse/MEVENIDE-231
After several days research, finally I got Mevenide run in my Eclipse, and understand that Mevenide 0.4.0 is a bugful plugin. Although I can run Maven in Eclipse, I wouldn't do this now. Also Mevenide 0.4.0 seems the lastest version of Mevenide supported Eclipse. It shifts to other IDEs. PS. this bug seem commonly exists under Linux platform, Maven 1.0.2 and Eclipse 3.1+
Wednesday, September 12, 2007
Ubuntu with BEA Workshop Studio 10.1
An introduction how to install BEA Workshop 10.1 (Unnecessary to follow it under Ubuntu 7)
http://workshopstudio.bea.com/install/install.html#nxtrialactivation
Address to download BEA Workshop Studio 10.1
http://workshopstudio.bea.com/downloadNitroX.do
The free license BEA Workshop™ for WebLogic 10.1 only supports BEA WebLogic Server, which is the main different from Workshop Studio ()
"BEA Workshop Studio has all the same
features as BEA Workshop for WebLogic, but adds
the capability to develop, debug, deploy to BEA and
non-BEA server targets like Apache Tomcat, IBM
Websphere, Caucho Resin, Mortbay Jetty and
Redhat JBoss (in addition to BEA WebLogic Server)."
After you download the Workshop.bin, just double click the icon. It just works without any configuration.
Register with email, and wait 5 minutes to get the reply, then try the trial version for 30 days
Simply speaking, BEA Workshop is Eclipse with many plugins, but I still have to install SVN and Mevenide, again, Mevenide doesn't work, but with another error this time

I download my project uploaded by Eclipse 3.3, and it works well in Eclipse 3.2 which supplied by Workshop.
http://workshopstudio.bea.com/install/install.html#nxtrialactivation
Address to download BEA Workshop Studio 10.1
http://workshopstudio.bea.com/downloadNitroX.do
The free license BEA Workshop™ for WebLogic 10.1 only supports BEA WebLogic Server, which is the main different from Workshop Studio ()
"BEA Workshop Studio has all the same
features as BEA Workshop for WebLogic, but adds
the capability to develop, debug, deploy to BEA and
non-BEA server targets like Apache Tomcat, IBM
Websphere, Caucho Resin, Mortbay Jetty and
Redhat JBoss (in addition to BEA WebLogic Server)."
After you download the Workshop.bin, just double click the icon. It just works without any configuration.
Register with email, and wait 5 minutes to get the reply, then try the trial version for 30 days
Simply speaking, BEA Workshop is Eclipse with many plugins, but I still have to install SVN and Mevenide, again, Mevenide doesn't work, but with another error this time

I download my project uploaded by Eclipse 3.3, and it works well in Eclipse 3.2 which supplied by Workshop.
Tuesday, September 11, 2007
Subclipse stays on one Workspace
I changes my workspace in Eclipse, then find out the SVN doesn't work. I go back to my previous workspace, copy /.metadata to current workspace, then it is working now.
cp -r .metadata/ /home/ji/projects/
or you can try remove the .metadata under your current workspace
rm -r .metadata/
cp -r .metadata/ /home/ji/projects/
or you can try remove the .metadata under your current workspace
rm -r .metadata/
Saturday, September 08, 2007
Add plugin for Maven in Ubuntu
If you put your Maven in under /opt or any other folder needed root to modify, you will need to be root to add a plugin for Maven in Ubuntu
####To start a root terminal:
gksudo gnome-terminal
export MAVEN_HOME=/opt/maven
export MAVEN_REPO=/home/ji/.maven/repository
export MAVEN_OPTS='-Xms256m -Xmx512m -XX:PermSize=64m -XX:MaxPermSize=128m'
export PATH=$PATH:$MAVEN_HOME/bin
maven plugin:download -DgroupId=maven-plugins -DartifactId=maven-axis-plugin -Dversion=0.7
####This creates a new Maven repository under /root, I don't know how to change it back to my normal user repository.
This is the server I use to download plugin:
http://mirrors.ibiblio.org/pub/mirrors/maven/maven-plugins/plugins/
Don't try to put a plugin straight to Maven plugin folder, it crashes Maven.
My Eclipse still doesn't work in using Maven plugin~~~!!! Is it possible my Maven too old for Eclipse 3.3.
Why don't we use higher version of Sakai, so that it can support Maven 2?
The answer to this is, till now the lastest version of Sakai only supports Maven 1.0.2 well.
####To start a root terminal:
gksudo gnome-terminal
export MAVEN_HOME=/opt/maven
export MAVEN_REPO=/home/ji/.maven/repository
export MAVEN_OPTS='-Xms256m -Xmx512m -XX:PermSize=64m -XX:MaxPermSize=128m'
export PATH=$PATH:$MAVEN_HOME/bin
maven plugin:download -DgroupId=maven-plugins -DartifactId=maven-axis-plugin -Dversion=0.7
####This creates a new Maven repository under /root, I don't know how to change it back to my normal user repository.
This is the server I use to download plugin:
http://mirrors.ibiblio.org/pub/mirrors/maven/maven-plugins/plugins/
Don't try to put a plugin straight to Maven plugin folder, it crashes Maven.
My Eclipse still doesn't work in using Maven plugin~~~!!! Is it possible my Maven too old for Eclipse 3.3.
Why don't we use higher version of Sakai, so that it can support Maven 2?
The answer to this is, till now the lastest version of Sakai only supports Maven 1.0.2 well.
Friday, September 07, 2007

Thursday, September 06, 2007
Using Maven
Setup SVN in Eclipse
Setup Maven 1.0.2
Add these lines below in a file called project.properties, so that your can run the genapp under a folder with this file in.
maven.xdoc.date = left
## maven.xdoc.version = ${pom.currentVersion}
custom.zipsource = true
maven.repo.remote=http://mirrors.ibiblio.org/pub/mirrors/maven/,http://source.sakaiproject.org/maven/
Refer to Massol, genapp is a plug-in to Maven, to check whether you have this plug-in, run
maven -g grep genapp
##Credit to San
Now I start to worry if the network doesn't work, what things can I do with Maven.
Ubuntu
To do copy and paste from window to window as root permission, run this:
sudo nautilus
##Credit to Hank
Maven POM description
http://maven.apache.org/maven-1.x/reference/maven-model/3.0.2/maven.html
Setup Maven 1.0.2
Add these lines below in a file called project.properties, so that your can run the genapp under a folder with this file in.
maven.xdoc.date = left
## maven.xdoc.version = ${pom.currentVersion}
custom.zipsource = true
maven.repo.remote=http://mirrors.ibiblio.org/pub/mirrors/maven/,http://source.sakaiproject.org/maven/
Refer to Massol
maven -g grep genapp
##Credit to San
Now I start to worry if the network doesn't work, what things can I do with Maven.
Ubuntu
To do copy and paste from window to window as root permission, run this:
sudo nautilus
##Credit to Hank
Maven POM description
http://maven.apache.org/maven-1.x/reference/maven-model/3.0.2/maven.html
Wednesday, August 29, 2007
Use Case
Background Introduction
Second hand textbook has potential market in every university. Although there are many big C2C online selling companies out there, like eBay, some students still prefer to buy locally, which saves the delivery expense and is easier to make a payment.
Description
A local bookstore can deploy a used book sell online website, which utilizes information communication technology and has the convenience provided by local trading. Buyer can check detail of each book on the website before he/she go to the store, and seller can leave a book in the bookstore with predefined price. Each transaction is through the bookstore. Buyer and seller do not have to make an appointment to meet any more.
Scope
This component is a part of an entire online selling system. It builds the entry and update function for bookstore staff, browsing function for buyer to find a correct book.
Online placing sell, order and updating function from buyer or seller are out of the boundary. Also, there is no search function for browser to search a particular book for sell.
Actors & Goals
Bookstore (Direct Actor): Keeps buyer and seller’s membership. Propagate itself, or generate some profit from transaction.
Buyer (Direct Actor): Easy to find a book and get the up-to-date information. Does transaction with less time constrain.
Seller: Get a platform with intense demand. No time constrain as no appointment.
Use Case
1. A seller hand a textbook to the bookstore located near university, and give a price to the book.
2. Bookstore staff takes picture and makes description of that book, classify it to a course. Then upload this sell onto the website. (MVC and write database)
3. Buyer browses the website, follow the course classification then check all those available books under one course, record a book he/she wants to buy. (MVC with database read)
4. Buyer goes to bookstore, ask for that particular book and pay. (Delete the record in database)
5. Seller is notified to collect money from bookstore.
Extend
In book’s description, staff uses a multiple choice to mark a book’s current condition. (unbias)
Bookstore staff can use barcode to identify a particular book.
Seller can leave and update a description and price directly on the store website.
Buyer can place an order directly online.
Potential Project Components to Integrate
(This part is not in my individual work, but can be handled by other team member)
Bookstore can notify seller by email or SMS after book sold.
A search engine should be built
A auction function can be used.
Integrate with library book DB, student account DB and study unit portal (sakai).
Actually the best actor of the bookstore is the library, which keeps a book database, customer (student) database. This also enhances the payment and trust. And the most important thing is that, unlike most second hand bookstores work on large margin or commission fee between buying and selling price, this service can be free to students.
Second hand textbook has potential market in every university. Although there are many big C2C online selling companies out there, like eBay, some students still prefer to buy locally, which saves the delivery expense and is easier to make a payment.
Description
A local bookstore can deploy a used book sell online website, which utilizes information communication technology and has the convenience provided by local trading. Buyer can check detail of each book on the website before he/she go to the store, and seller can leave a book in the bookstore with predefined price. Each transaction is through the bookstore. Buyer and seller do not have to make an appointment to meet any more.
Scope
This component is a part of an entire online selling system. It builds the entry and update function for bookstore staff, browsing function for buyer to find a correct book.
Online placing sell, order and updating function from buyer or seller are out of the boundary. Also, there is no search function for browser to search a particular book for sell.
Actors & Goals
Bookstore (Direct Actor): Keeps buyer and seller’s membership. Propagate itself, or generate some profit from transaction.
Buyer (Direct Actor): Easy to find a book and get the up-to-date information. Does transaction with less time constrain.
Seller: Get a platform with intense demand. No time constrain as no appointment.
Use Case
1. A seller hand a textbook to the bookstore located near university, and give a price to the book.
2. Bookstore staff takes picture and makes description of that book, classify it to a course. Then upload this sell onto the website. (MVC and write database)
3. Buyer browses the website, follow the course classification then check all those available books under one course, record a book he/she wants to buy. (MVC with database read)
4. Buyer goes to bookstore, ask for that particular book and pay. (Delete the record in database)
5. Seller is notified to collect money from bookstore.
Extend
In book’s description, staff uses a multiple choice to mark a book’s current condition. (unbias)
Bookstore staff can use barcode to identify a particular book.
Seller can leave and update a description and price directly on the store website.
Buyer can place an order directly online.
Potential Project Components to Integrate
(This part is not in my individual work, but can be handled by other team member)
Bookstore can notify seller by email or SMS after book sold.
A search engine should be built
A auction function can be used.
Integrate with library book DB, student account DB and study unit portal (sakai).
Actually the best actor of the bookstore is the library, which keeps a book database, customer (student) database. This also enhances the payment and trust. And the most important thing is that, unlike most second hand bookstores work on large margin or commission fee between buying and selling price, this service can be free to students.
Sunday, August 19, 2007
A Book related to our lab work - Spring in Action
CRAIG WALLS, RYAN BREIDENBACH, 2005, Spring in Action
It discusses what we are trying to do in lab in the following chapter. I find it useful when you get confused in doing the lab work.
Chapter 8 Building the web layer - Getting started with Spring MVC
This chapter covers
■ Mapping requests to Spring controllers
■ Transparently binding form parameters
■ Validating form submissions
■ Adding functionality with interceptors
It discusses what we are trying to do in lab in the following chapter. I find it useful when you get confused in doing the lab work.
Chapter 8 Building the web layer - Getting started with Spring MVC
This chapter covers
■ Mapping requests to Spring controllers
■ Transparently binding form parameters
■ Validating form submissions
■ Adding functionality with interceptors
Saturday, August 18, 2007
GCC
To setup the C environment in Ubuntu, so that you can compile C file
sudo apt-get install build-essential
sudo apt-get install build-essential
Wednesday, August 15, 2007
Junit test failed in terminal
Use my Eclipse to run junit:
No problem:
Buildfile: /home/ji/projects/springapp/build.xml
build:
[javac] Compiling 1 source file to /home/ji/projects/springapp/war/WEB-INF/classes
clearData:
[echo] CLEAR DATA USING: org.hsqldb.jdbcDriver jdbc:hsqldb:db/test
[sql] Executing commands
[sql] 1 of 1 SQL statements executed successfully
loadData:
[echo] LOAD DATA USING: org.hsqldb.jdbcDriver jdbc:hsqldb:db/test
[sql] Executing commands
[sql] 5 of 5 SQL statements executed successfully
junit:
[junit] Running tests.TestProductManager
[junit] Testsuite: tests.TestProductManager
[junit] Tests run: 2, Failures: 0, Errors: 0, Time elapsed: 0.035 sec
[junit] Tests run: 2, Failures: 0, Errors: 0, Time elapsed: 0.035 sec
[junit] Running tests.TestProductManagerDaoJdbc
[junit] Testsuite: tests.TestProductManagerDaoJdbc
[junit] 2007-08-15 00:55:31,921 INFO [org.springframework.jdbc.datasource.DriverManagerDataSource] -
[junit] 2007-08-15 00:55:31,922 INFO [db.ProductManagerDaoJdbc] -
[junit] 2007-08-15 00:55:32,387 INFO [db.ProductManagerDaoJdbc] -
[junit] 2007-08-15 00:55:32,403 INFO [db.ProductManagerDaoJdbc] -
[junit] 2007-08-15 00:55:32,403 INFO [db.ProductManagerDaoJdbc] -
[junit] 2007-08-15 00:55:32,406 INFO [org.springframework.jdbc.datasource.DriverManagerDataSource] -
[junit] 2007-08-15 00:55:32,407 INFO [db.ProductManagerDaoJdbc] -
[junit] Tests run: 2, Failures: 0, Errors: 0, Time elapsed: 0.771 sec
[junit] Tests run: 2, Failures: 0, Errors: 0, Time elapsed: 0.771 sec
[junit] ------------- Standard Output ---------------
[junit] 2007-08-15 00:55:31,921 INFO [org.springframework.jdbc.datasource.DriverManagerDataSource] -
[junit] 2007-08-15 00:55:31,922 INFO [db.ProductManagerDaoJdbc] -
[junit] 2007-08-15 00:55:32,387 INFO [db.ProductManagerDaoJdbc] -
[junit] 2007-08-15 00:55:32,403 INFO [db.ProductManagerDaoJdbc] -
[junit] 2007-08-15 00:55:32,403 INFO [db.ProductManagerDaoJdbc] -
[junit] 2007-08-15 00:55:32,406 INFO [org.springframework.jdbc.datasource.DriverManagerDataSource] -
[junit] 2007-08-15 00:55:32,407 INFO [db.ProductManagerDaoJdbc] -
[junit] ------------- ---------------- ---------------
[junit] Running tests.TestSpringappController
[junit] Testsuite: tests.TestSpringappController
[junit] 2007-08-15 00:55:32,535 INFO [org.springframework.core.CollectionFactory] -
[junit] 2007-08-15 00:55:32,577 INFO [org.springframework.beans.factory.xml.XmlBeanDefinitionReader] -
[junit] 2007-08-15 00:55:32,691 INFO [org.springframework.context.support.FileSystemXmlApplicationContext] -
[junit] 2007-08-15 00:55:32,709 INFO [org.springframework.context.support.FileSystemXmlApplicationContext] - <6 hashcode="6147782]">
[junit] 2007-08-15 00:55:32,719 INFO [org.springframework.context.support.FileSystemXmlApplicationContext] -
[junit] 2007-08-15 00:55:32,722 INFO [org.springframework.context.support.FileSystemXmlApplicationContext] -
[junit] 2007-08-15 00:55:32,725 INFO [org.springframework.beans.factory.support.DefaultListableBeanFactory] -
[junit] 2007-08-15 00:55:32,802 INFO [web.SpringappController] -
[junit] 2007-08-15 00:55:32,803 INFO [web.SpringappController] -
[junit] Tests run: 1, Failures: 0, Errors: 0, Time elapsed: 0.376 sec
[junit] Tests run: 1, Failures: 0, Errors: 0, Time elapsed: 0.376 sec
[junit] ------------- Standard Output ---------------
[junit] 2007-08-15 00:55:32,535 INFO [org.springframework.core.CollectionFactory] -
[junit] 2007-08-15 00:55:32,577 INFO [org.springframework.beans.factory.xml.XmlBeanDefinitionReader] -
[junit] 2007-08-15 00:55:32,691 INFO [org.springframework.context.support.FileSystemXmlApplicationContext] -
[junit] 2007-08-15 00:55:32,709 INFO [org.springframework.context.support.FileSystemXmlApplicationContext] - <6 hashcode="6147782]">
[junit] 2007-08-15 00:55:32,719 INFO [org.springframework.context.support.FileSystemXmlApplicationContext] -
[junit] 2007-08-15 00:55:32,722 INFO [org.springframework.context.support.FileSystemXmlApplicationContext] -
[junit] 2007-08-15 00:55:32,725 INFO [org.springframework.beans.factory.support.DefaultListableBeanFactory] -
[junit] 2007-08-15 00:55:32,802 INFO [web.SpringappController] -
[junit] 2007-08-15 00:55:32,803 INFO [web.SpringappController] -
[junit] ------------- ---------------- ---------------
BUILD SUCCESSFUL
Total time: 3 seconds
When I use the terminal command:
ant junit
Error comes out:
Buildfile: build.xml
build:
[javac] Compiling 1 source file to /home/ji/projects/springapp/war/WEB-INF/classes
clearData:
[echo] CLEAR DATA USING: org.hsqldb.jdbcDriver jdbc:hsqldb:db/test
[sql] Executing commands
[sql] 1 of 1 SQL statements executed successfully
loadData:
[echo] LOAD DATA USING: org.hsqldb.jdbcDriver jdbc:hsqldb:db/test
[sql] Executing commands
[sql] 5 of 5 SQL statements executed successfully
junit:
BUILD FAILED
/home/ji/projects/springapp/build.xml:175: java.lang.NoClassDefFoundError: org/apache/tools/ant/types/ResourceCollection
I think the reasons can be they use different junit.jar files, or my Ant did not configure well. Anyway, the springapp website runs without any problem. I install
Apache Ant version 1.6.5 compiled on July 5 2006
No problem:
Buildfile: /home/ji/projects/springapp/build.xml
build:
[javac] Compiling 1 source file to /home/ji/projects/springapp/war/WEB-INF/classes
clearData:
[echo] CLEAR DATA USING: org.hsqldb.jdbcDriver jdbc:hsqldb:db/test
[sql] Executing commands
[sql] 1 of 1 SQL statements executed successfully
loadData:
[echo] LOAD DATA USING: org.hsqldb.jdbcDriver jdbc:hsqldb:db/test
[sql] Executing commands
[sql] 5 of 5 SQL statements executed successfully
junit:
[junit] Running tests.TestProductManager
[junit] Testsuite: tests.TestProductManager
[junit] Tests run: 2, Failures: 0, Errors: 0, Time elapsed: 0.035 sec
[junit] Tests run: 2, Failures: 0, Errors: 0, Time elapsed: 0.035 sec
[junit] Running tests.TestProductManagerDaoJdbc
[junit] Testsuite: tests.TestProductManagerDaoJdbc
[junit] 2007-08-15 00:55:31,921 INFO [org.springframework.jdbc.datasource.DriverManagerDataSource] -
[junit] 2007-08-15 00:55:31,922 INFO [db.ProductManagerDaoJdbc] -
[junit] 2007-08-15 00:55:32,387 INFO [db.ProductManagerDaoJdbc] -
[junit] 2007-08-15 00:55:32,403 INFO [db.ProductManagerDaoJdbc] -
[junit] 2007-08-15 00:55:32,403 INFO [db.ProductManagerDaoJdbc] -
[junit] 2007-08-15 00:55:32,406 INFO [org.springframework.jdbc.datasource.DriverManagerDataSource] -
[junit] 2007-08-15 00:55:32,407 INFO [db.ProductManagerDaoJdbc] -
[junit] Tests run: 2, Failures: 0, Errors: 0, Time elapsed: 0.771 sec
[junit] Tests run: 2, Failures: 0, Errors: 0, Time elapsed: 0.771 sec
[junit] ------------- Standard Output ---------------
[junit] 2007-08-15 00:55:31,921 INFO [org.springframework.jdbc.datasource.DriverManagerDataSource] -
[junit] 2007-08-15 00:55:31,922 INFO [db.ProductManagerDaoJdbc] -
[junit] 2007-08-15 00:55:32,387 INFO [db.ProductManagerDaoJdbc] -
[junit] 2007-08-15 00:55:32,403 INFO [db.ProductManagerDaoJdbc] -
[junit] 2007-08-15 00:55:32,403 INFO [db.ProductManagerDaoJdbc] -
[junit] 2007-08-15 00:55:32,406 INFO [org.springframework.jdbc.datasource.DriverManagerDataSource] -
[junit] 2007-08-15 00:55:32,407 INFO [db.ProductManagerDaoJdbc] -
[junit] ------------- ---------------- ---------------
[junit] Running tests.TestSpringappController
[junit] Testsuite: tests.TestSpringappController
[junit] 2007-08-15 00:55:32,535 INFO [org.springframework.core.CollectionFactory] -
[junit] 2007-08-15 00:55:32,577 INFO [org.springframework.beans.factory.xml.XmlBeanDefinitionReader] -
[junit] 2007-08-15 00:55:32,691 INFO [org.springframework.context.support.FileSystemXmlApplicationContext] -
[junit] 2007-08-15 00:55:32,709 INFO [org.springframework.context.support.FileSystemXmlApplicationContext] - <6 hashcode="6147782]">
[junit] 2007-08-15 00:55:32,719 INFO [org.springframework.context.support.FileSystemXmlApplicationContext] -
[junit] 2007-08-15 00:55:32,722 INFO [org.springframework.context.support.FileSystemXmlApplicationContext] -
[junit] 2007-08-15 00:55:32,725 INFO [org.springframework.beans.factory.support.DefaultListableBeanFactory] -
[junit] 2007-08-15 00:55:32,802 INFO [web.SpringappController] -
[junit] 2007-08-15 00:55:32,803 INFO [web.SpringappController] -
[junit] Tests run: 1, Failures: 0, Errors: 0, Time elapsed: 0.376 sec
[junit] Tests run: 1, Failures: 0, Errors: 0, Time elapsed: 0.376 sec
[junit] ------------- Standard Output ---------------
[junit] 2007-08-15 00:55:32,535 INFO [org.springframework.core.CollectionFactory] -
[junit] 2007-08-15 00:55:32,577 INFO [org.springframework.beans.factory.xml.XmlBeanDefinitionReader] -
[junit] 2007-08-15 00:55:32,691 INFO [org.springframework.context.support.FileSystemXmlApplicationContext] -
[junit] 2007-08-15 00:55:32,709 INFO [org.springframework.context.support.FileSystemXmlApplicationContext] - <6 hashcode="6147782]">
[junit] 2007-08-15 00:55:32,719 INFO [org.springframework.context.support.FileSystemXmlApplicationContext] -
[junit] 2007-08-15 00:55:32,722 INFO [org.springframework.context.support.FileSystemXmlApplicationContext] -
[junit] 2007-08-15 00:55:32,725 INFO [org.springframework.beans.factory.support.DefaultListableBeanFactory] -
[junit] 2007-08-15 00:55:32,802 INFO [web.SpringappController] -
[junit] 2007-08-15 00:55:32,803 INFO [web.SpringappController] -
[junit] ------------- ---------------- ---------------
BUILD SUCCESSFUL
Total time: 3 seconds
When I use the terminal command:
ant junit
Error comes out:
Buildfile: build.xml
build:
[javac] Compiling 1 source file to /home/ji/projects/springapp/war/WEB-INF/classes
clearData:
[echo] CLEAR DATA USING: org.hsqldb.jdbcDriver jdbc:hsqldb:db/test
[sql] Executing commands
[sql] 1 of 1 SQL statements executed successfully
loadData:
[echo] LOAD DATA USING: org.hsqldb.jdbcDriver jdbc:hsqldb:db/test
[sql] Executing commands
[sql] 5 of 5 SQL statements executed successfully
junit:
BUILD FAILED
/home/ji/projects/springapp/build.xml:175: java.lang.NoClassDefFoundError: org/apache/tools/ant/types/ResourceCollection
I think the reasons can be they use different junit.jar files, or my Ant did not configure well. Anyway, the springapp website runs without any problem. I install
Apache Ant version 1.6.5 compiled on July 5 2006
Saturday, August 11, 2007
Stop working
http://weg.ee.usyd.edu.au/courses/ebus5003/
This afternoon, I try the course website, but it doesn't work. I can't do the lab without this~~~~!!!!!
Another problem is that I have copied Spring file from lab computer. When I extract it in my desktop at home, it comes out an error. I really need the junit.jar from Spring to continue.
Maybe Saturday is not the right day to work.
This afternoon, I try the course website, but it doesn't work. I can't do the lab without this~~~~!!!!!
Another problem is that I have copied Spring file from lab computer. When I extract it in my desktop at home, it comes out an error. I really need the junit.jar from Spring to continue.
Maybe Saturday is not the right day to work.
Friday, August 03, 2007
Here is a brand new chapter
I install Ubuntu 7.04 on my desktop at home to do this lab. Since I used up all the quota in accessing internet, I downloaded all the software in lab and planned to install them into my Ubuntu just like what we usually do in MS Windows that straight forward. But I am wrong.
Many software in Ubuntu is self-managed by the system. It can automatically download online and install it on a click. But if you'd got a pack on hand to install, it seems not that straight forward.
First, in Ubuntu, you can't use RPM pack used normally in Fedora or some other popular Linux systems. In installation, you just uncompress the pack you downloaded online, and put it somewhere in the system. The hard thing is to specify the environment value. Here is what I added to
~/.bashrc
export JAVA_HOME=/usr/lib/j2sdk1.5-sun
export CLASSPATH=/usr/lib/j2sdk1.5-sun/lib
export PATH=$PATH:/usr/lib/j2sdk1.5-sun/bin
export CATALINA_HOME=/opt/tomcat
There are some reminders when using the lab computer
bash
source /eelabs/ebus5003/profile
In my account, I always have to type these in my terminal to start and work. No idea!!!!
fs listquota
check your disk space
proxy:
http://www.eelab.usyd.edu.au/proxy.pac
In Firefox
build.properties and build.xml should be under the same folder
In step10, make sure to specify where you want to put the log file. In my case, it is like this:
log4j.appender.logfile.File=/opt/tomcat/logs/springapp.log
If you make it wrong, you can't find the file, and nothing indicates it was going wrong!!!!!!!!
Until now, luckily, part1 is finished. I encounter Linux, Ant and Spring. I believe they are good tools once you can set them up.
Many software in Ubuntu is self-managed by the system. It can automatically download online and install it on a click. But if you'd got a pack on hand to install, it seems not that straight forward.
First, in Ubuntu, you can't use RPM pack used normally in Fedora or some other popular Linux systems. In installation, you just uncompress the pack you downloaded online, and put it somewhere in the system. The hard thing is to specify the environment value. Here is what I added to
~/.bashrc
export JAVA_HOME=/usr/lib/j2sdk1.5-sun
export CLASSPATH=/usr/lib/j2sdk1.5-sun/lib
export PATH=$PATH:/usr/lib/j2sdk1.5-sun/bin
export CATALINA_HOME=/opt/tomcat
There are some reminders when using the lab computer
bash
source /eelabs/ebus5003/profile
In my account, I always have to type these in my terminal to start and work. No idea!!!!
fs listquota
check your disk space
proxy:
http://www.eelab.usyd.edu.au/proxy.pac
In Firefox
build.properties and build.xml should be under the same folder
In step10, make sure to specify where you want to put the log file. In my case, it is like this:
log4j.appender.logfile.File=/opt/tomcat/logs/springapp.log
If you make it wrong, you can't find the file, and nothing indicates it was going wrong!!!!!!!!
Until now, luckily, part1 is finished. I encounter Linux, Ant and Spring. I believe they are good tools once you can set them up.
Tuesday, July 10, 2007
4 yrs old laptop System
CPU-Z 1.40.5 report file | ||||||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||||||
|
New System Profile
CPU-Z 1.40.5 report file | ||||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||||
|
Subscribe to:
Comments (Atom)